Stateless Transport Tunneling Protocol
Stateless Transport Tunneling(STT) 是由新創公司 Nicira 於 2012 年 2 月所單獨提出的草案, 並被該被公司申請專利,目前更新為第四版, 於 2012 年 7 月 Nicira 被 VMWare 所併購, 目前本 Internet Draft 也改為由 VMWare 所提案。
STT 主要是要解決封包分段的問題,雖然 NVGRE 已盡量嘗試避免, 但封包仍然會有被分段的可能, 為此,STT 利用現今網路卡對TCP 分段卸載(TCP Segmentation Offload,TSO)的支援功能, 希望透過現在的硬體網路卡(Network Interface Card, NIC)來改善封裝的效能,它是運行在 IP 上的協定, 封裝了一層類似 TCP(TCP-like)的表頭之內, 目的是能透過現代網卡都支援的 TSO 來改善現有通道協定封裝的效能問題, 如此一來封包的分段及重組的工作均交由 NIC 處理, 而 STT 則利用此特性將協定設計的與 TCP header 標頭結構相容, 不會影響到隧道端點的運作效能,而此協運運行的過程都是無狀態, 不需要像 TCP 一樣需要先建立建線才通訊, 而實際執行 STT 封裝與解封裝的端點是在虛擬交換器(Virtual Switch)上。
此草案目前已經實作在 Open vSwitch 上,已有國外的技術網站進行測試比較, 發現 STT 完全不影響網路傳輸吞吐量與 CPU 效能, 吞吐量比運行在 Open vSwitch 上的 GRE 高上許多,而且執行起來對系統的 CPU 負載也較低, 足見 STT 在技術上的優越性。
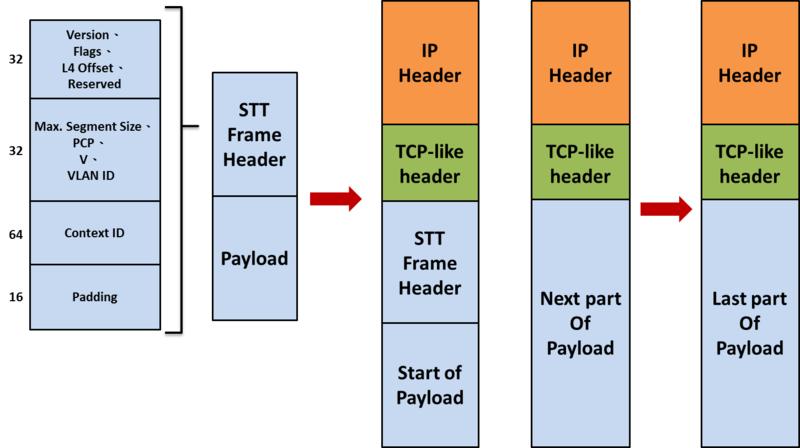
STT 封包格式如下,在 STT header 內保留了 64 bit 的 Context ID, 因此可辦識的虛擬網路數量更為可觀,而在 TCP-like 表頭的 destination port 正向 IANA 申請固定號碼中, 以作為辦識 STT 的依據,Source port 則是與 VXLAN 裡 UDP 的 Source port 一樣, 可用來作為等價多路徑由的依據,在廣播與群播的處理上則是與 NVGRE 相同, 底層的網路不必然一定要支援 IP 群播。
TSO(TCP Segmentation Offload)
TSO(TCP Segmentation Offload) 是一種利用 NIC 分割大封包, 減少 CPU 負荷的一種技術,也被叫做 LSO(Large Segment Offload), 如果封包的類型只能是 TCP,則被稱之為 TSO, 如果硬體支援 TSO 功能的話,也需要同時支援硬體的 TCP 校驗計算和分散,聚集(Scatter Gather)功能。
TSO 的實現需要一些基本條件,而這些其實是由軟體和硬體結合起來完成的, 對於硬體,具體來說,硬體對夠能對大的封包進行分段, 分段之後,還要能對每個分段附著的相關 header。
TSO 的支援主要有需要下列的幾步:
1.如果 NIC 支援 TSO 功能,需要宣告 NIC 支援 TSO, 這是通過以 NETIFFTSO 標誌設置 netdevice structure 的 features 欄位來表明, 例如,在 benet(drivers/net/benet/bemain.c) 網卡的驅動程序中, 設置 NETIFFTSO 的代碼如下:
static void be_netdev_init(struct net_device *netdev) {
struct be_adapter *adapter = netdev_priv(netdev);
netdev->features |= NETIF_F_SG | NETIF_F_HW_VLAN_RX | NETIF_F_TSO | NETIF_F_HW_VLAN_TX | NETIF_F_HW_VLAN_FILTER | NETIF_F_HW_CSUM | NETIF_F_GRO | NETIF_F_TSO6;
netdev->vlan_features |= NETIF_F_SG | NETIF_F_TSO | NETIF_F_HW_CSUM;
netdev->flags |= IFF_MULTICAST;
adapter->rx_csum = true;
/* Default settings for Rx and Tx flow control */
adapter->rx_fc = true;
adapter->tx_fc = true;
netif_set_gso_max_size(netdev, 65535);
BE_SET_NETDEV_OPS(netdev, &be_netdev_ops);
SET_ETHTOOL_OPS(netdev, &be_ethtool_ops);
netif_napi_add(netdev, &adapter->rx_eq.napi, be_poll_rx, BE_NAPI_WEIGHT);
netif_napi_add(netdev, &adapter->tx_eq.napi, be_poll_tx_mcc, BE_NAPI_WEIGHT);
netif_carrier_off(netdev);
netif_stop_queue(netdev);
}
在上面的程式碼中,同時也用 netifsetgsomax size 函數設定了 netdevice 的 gsomaxsize 欄位。 該欄位代表 NIC 一次能處理的最大 buffer 大小,一般該值為 64 KB, 這意味著只要 TCP 的數據大小不超過 64 KB,就不用在內核(kernel)分段, 而只需一次性的推送到 NIC,由 NIC 去執行分段功能。
2.當一個 TCP 的 socket 被創建,其中一個職責就是設定該連線的能力, 在網路層的 socket 的表示是 struck sock,其中有一個欄位 skroutecaps 標示該連接的能力, 在 TCP 的三向交握完成後,將基於 NIC 的能力和連接來設定該欄位。
/* This will initiate an outgoing connection. */
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) {
……
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
……
}
上述程式中的 sksetupcaps() 函數則設定了上面所說的 skroutecaps 欄位, 同時也檢查了硬體是否支持分散 - 聚集功能和硬件校驗計算功能。 需要這 2 個功能的原因是:Buffer 可能不在一個內存頁面上,所以需要分散 - 聚集功能, 而分段後的每個分段需要重新計算 checksum,因此需要硬體支持校驗計算。
3.現在,一切的準備工作都已經做好了,當實際的數據需要傳輸時,需要使用我們設定好的 gsomaxsize, 我們知道,TCP 向 IP 層發送數據會考慮 MSS,使得發送的 IP 包在 MTU 內,不用分段。 而 TSO 設定的 gsomaxsize 就影響該過程,這主要是在計算 mssnow 字段時使用。 如果 Kernel 不支援 TSO 功能,mssnow 的最大值為 "MTU – HLENS", 而在支援 TSO 的情況下,mssnow 的最大值為 "gsomax_size - HLENS", 這樣,從網絡層帶驅動的路徑就被打通了。
Ref.
- http://networkheresy.com/2012/06/08/the-overhead-of-software-tunneling/
- http://tech.hexun.com.tw/2011-01-04/126555670.html
- http://en.wikipedia.org/wiki/Largereceiveoffload
- http://en.wikipedia.org/wiki/Largesegmentoffload
- http://zh.wikipedia.org/wiki/%E6%9C%80%E5%A4%A7%E4%BC%A0%E8%BE%93%E5%8D%95%E5%85%83
- http://chunchaichang.blogspot.tw/2012/01/mtu.html
- http://en.wikipedia.org/wiki/MaximumSegmentSize
- http://publib.boulder.ibm.com/infocenter/pseries/v5r3/index.jsp?topic=/com.ibm.aix.prftungd/doc/prftungd/tcpmaxsegsizetuning.htm