Network and Tunneling
|
Dec 9, 2013
Stateless Transport Tunneling(STT)
是由新創公司 Nicira 於 2012 年 2 月所單獨提出的草案,
並被該被公司申請專利,目前更新為第四版,
於 2012 年 7 月 Nicira 被 VMWare 所併購,
目前本 Internet Draft 也改為由 VMWare 所提案。
STT 主要是要解決封包分段的問題,雖然 NVGRE 已盡量嘗試避免,
但封包仍然會有被分段的可能,
為此,STT 利用現今網路卡對TCP 分段卸載(TCP Segmentation Offload,TSO)的支援功能,
希望透過現在的硬體網路卡(Network Interface Card, NIC)來改善封裝的效能,它是運行在 IP 上的協定,
封裝了一層類似 TCP(TCP-like)的表頭之內,
目的是能透過現代網卡都支援的 TSO 來改善現有通道協定封裝的效能問題,
如此一來封包的分段及重組的工作均交由 NIC 處理,
而 STT 則利用此特性將協定設計的與 TCP header 標頭結構相容,
不會影響到隧道端點的運作效能,而此協運運行的過程都是無狀態,
不需要像 TCP 一樣需要先建立建線才通訊,
而實際執行 STT 封裝與解封裝的端點是在虛擬交換器(Virtual Switch)上。
此草案目前已經實作在 Open vSwitch 上,已有國外的技術網站進行測試比較,
發現 STT 完全不影響網路傳輸吞吐量與 CPU 效能,
吞吐量比運行在 Open vSwitch 上的 GRE 高上許多,而且執行起來對系統的 CPU 負載也較低,
足見 STT 在技術上的優越性。
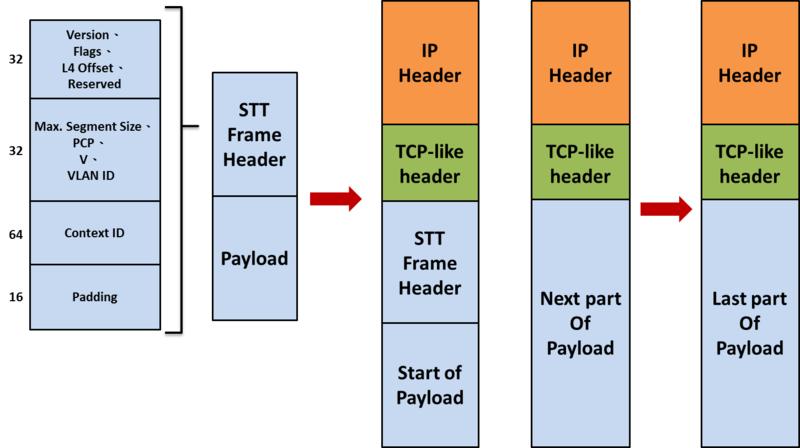
STT 封包格式如下,在 STT header 內保留了 64 bit 的 Context ID,
因此可辦識的虛擬網路數量更為可觀,而在 TCP-like 表頭的 destination port 正向 IANA 申請固定號碼中,
以作為辦識 STT 的依據,Source port 則是與 VXLAN 裡 UDP 的 Source port 一樣,
可用來作為等價多路徑由的依據,在廣播與群播的處理上則是與 NVGRE 相同,
底層的網路不必然一定要支援 IP 群播。
TSO(TCP Segmentation Offload)
TSO(TCP Segmentation Offload) 是一種利用 NIC 分割大封包,
減少 CPU 負荷的一種技術,也被叫做 LSO(Large Segment Offload),
如果封包的類型只能是 TCP,則被稱之為 TSO,
如果硬體支援 TSO 功能的話,也需要同時支援硬體的 TCP 校驗計算和分散,聚集(Scatter Gather)功能。
TSO 的實現需要一些基本條件,而這些其實是由軟體和硬體結合起來完成的,
對於硬體,具體來說,硬體對夠能對大的封包進行分段,
分段之後,還要能對每個分段附著的相關 header。
TSO 的支援主要有需要下列的幾步:
1.如果 NIC 支援 TSO 功能,需要宣告 NIC 支援 TSO, 這是通過以 NETIFFTSO 標誌設置 netdevice structure 的 features 欄位來表明, 例如,在 benet(drivers/net/benet/bemain.c) 網卡的驅動程序中, 設置 NETIFFTSO 的代碼如下:
static void be_netdev_init(struct net_device *netdev) {
struct be_adapter *adapter = netdev_priv(netdev);
netdev->features |= NETIF_F_SG | NETIF_F_HW_VLAN_RX | NETIF_F_TSO | NETIF_F_HW_VLAN_TX | NETIF_F_HW_VLAN_FILTER | NETIF_F_HW_CSUM | NETIF_F_GRO | NETIF_F_TSO6;
netdev->vlan_features |= NETIF_F_SG | NETIF_F_TSO | NETIF_F_HW_CSUM;
netdev->flags |= IFF_MULTICAST;
adapter->rx_csum = true;
/* Default settings for Rx and Tx flow control */
adapter->rx_fc = true;
adapter->tx_fc = true;
netif_set_gso_max_size(netdev, 65535);
BE_SET_NETDEV_OPS(netdev, &be_netdev_ops);
SET_ETHTOOL_OPS(netdev, &be_ethtool_ops);
netif_napi_add(netdev, &adapter->rx_eq.napi, be_poll_rx, BE_NAPI_WEIGHT);
netif_napi_add(netdev, &adapter->tx_eq.napi, be_poll_tx_mcc, BE_NAPI_WEIGHT);
netif_carrier_off(netdev);
netif_stop_queue(netdev);
}
在上面的程式碼中,同時也用 netifsetgsomax size 函數設定了 netdevice 的 gsomaxsize 欄位。
該欄位代表 NIC 一次能處理的最大 buffer 大小,一般該值為 64 KB,
這意味著只要 TCP 的數據大小不超過 64 KB,就不用在內核(kernel)分段,
而只需一次性的推送到 NIC,由 NIC 去執行分段功能。
2.當一個 TCP 的 socket 被創建,其中一個職責就是設定該連線的能力, 在網路層的 socket 的表示是 struck sock,其中有一個欄位 skroutecaps 標示該連接的能力, 在 TCP 的三向交握完成後,將基於 NIC 的能力和連接來設定該欄位。
/* This will initiate an outgoing connection. */
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) {
……
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
……
}
上述程式中的 sksetupcaps() 函數則設定了上面所說的 skroutecaps 欄位,
同時也檢查了硬體是否支持分散 - 聚集功能和硬件校驗計算功能。
需要這 2 個功能的原因是:Buffer 可能不在一個內存頁面上,所以需要分散 - 聚集功能,
而分段後的每個分段需要重新計算 checksum,因此需要硬體支持校驗計算。
3.現在,一切的準備工作都已經做好了,當實際的數據需要傳輸時,需要使用我們設定好的 gsomaxsize, 我們知道,TCP 向 IP 層發送數據會考慮 MSS,使得發送的 IP 包在 MTU 內,不用分段。 而 TSO 設定的 gsomaxsize 就影響該過程,這主要是在計算 mssnow 字段時使用。 如果 Kernel 不支援 TSO 功能,mssnow 的最大值為 "MTU – HLENS", 而在支援 TSO 的情況下,mssnow 的最大值為 "gsomax_size - HLENS", 這樣,從網絡層帶驅動的路徑就被打通了。
Ref.
- http://networkheresy.com/2012/06/08/the-overhead-of-software-tunneling/
- http://tech.hexun.com.tw/2011-01-04/126555670.html
- http://en.wikipedia.org/wiki/Largereceiveoffload
- http://en.wikipedia.org/wiki/Largesegmentoffload
- http://zh.wikipedia.org/wiki/%E6%9C%80%E5%A4%A7%E4%BC%A0%E8%BE%93%E5%8D%95%E5%85%83
- http://chunchaichang.blogspot.tw/2012/01/mtu.html
- http://en.wikipedia.org/wiki/MaximumSegmentSize
- http://publib.boulder.ibm.com/infocenter/pseries/v5r3/index.jsp?topic=/com.ibm.aix.prftungd/doc/prftungd/tcpmaxsegsizetuning.htm
Tunneling and Network
|
Dec 8, 2013
Network Virtualization using Generic Routing Encapsulation(NVGRE)
是由 Micrsoft 為首與 Intel、Dell、Broadcom、Arista 在 2011 年 9 月共同提出的 IETF 草案,
僅略晚 VXLAN 不到一個月,目前已修訂到第三版,
不同於 VXLAN 使用 UDP 封包格式
NVGRE 採用現有一般路由封裝(Generic Routing Encapsulation,GRE) 之格式,
隧道兩端點稱為網路虛擬化端點(Network Virtualization Edge,NVE)。
與 VXLAN 有相同程度上的雷同,因為兩個草案都是要解決類似的問題,
在大型資料心中心中多客戶的網路隔離問題。
Header Format
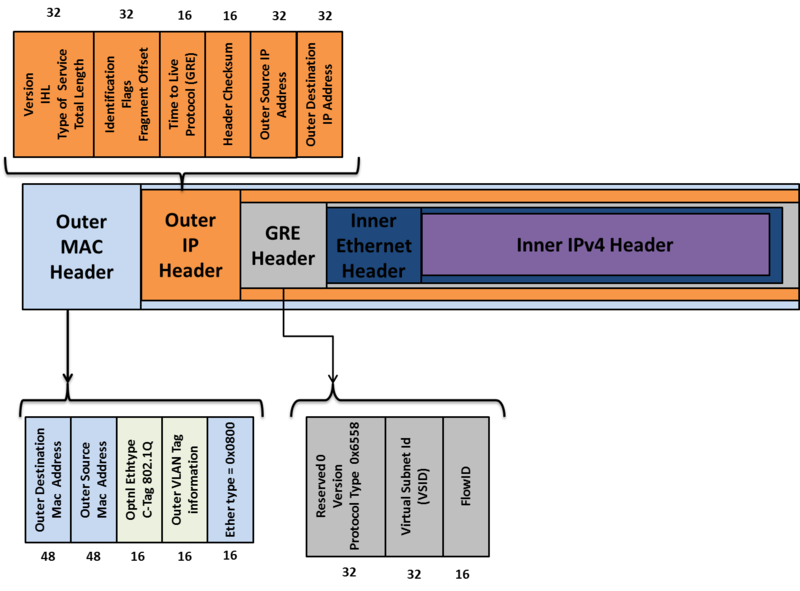
Outer Ethernet Header
Destination Address
用來設定 destination NVGRE endpoint 的 MAC address,如果 destination NVE 與 Source NVE 不屬於同一個 L3 的 domain 下的時候,這個欄位就會用來填入 next hop device(router) 的 MAC addrss。
VLAN
是一個可填可不填的欄位,如果有填的話就會就會利用 ethertype of 0x8100 來實作可隔離網路的 VLAN ID Tag。
IP Header
目前可以支援 IPv4 與 IPv6,
在這裡我們僅說明 IPv4 的封包格式,
其實這邊的封包格式與一般 IPv4 的封包格式相同,
只是這邊的傳輸都是建立在 NVE 與 NVE 之間。
Protocol
這邊會設定為 0x2F 表示,封包裡面的內容是 GRE 封包
Source IP
送出封包的來源 NVE
GRE header
NVGRE 是由 GRE header 來包覆被封裝的 inner ethernet 的封包,
Virtual Subnet ID(VSID)
24 bit 的欄位,用來代表不同 NVGRE 群組的編號,不同編號的 VSID 群組,不能互相溝通。
可支援超過一千六百萬個不同虛擬網路,遠大於 VLAN 4094 個的限制。
Flow ID
8 bit 的欄位,是用來識別不同的資料流,
然而現有的等價多路徑路由機制(Equal-Cost Multi path Routing, ECMP)僅根據 TCP/IP header 來辦識資料流,
並不支援 GRE header,因此在底層設備並未支援 FlowID 的檢視之前,
NVGRE 建議使用多個 NVE 實體 IP 位置來對應不同的資料流,
整體上來說,在負載平衡上的處理仍指不夠細緻。
例如當 NVE 收到封包是一個會檢查其目的乙太網路位置來查詢要送到哪個通道,
並且查詢來源乙太網路位址屬於哪位客戶,透過這兩個欄位(VSID、FlowID)來決定封包的傳送方式。
Inner ethernet header
與一般的 ethernet header 相同,
與 VXLAN 不同的是 inner ethernet header 並不支援 802.1Q VLAN。
Brocast、Muticast
在廣播和群播的處理上,NVGRE 可使用 IP 群播的機制,
若底層網路不支援 IP 群播,亦可用多重單點傳送來達成相同功能;
同時考量隧道封包機制會將增加整體封包長度,
若長度超過底層網路的最大傳輸單元(Maximum Transmission Unit,MTU)時封包會被強制分段(fragmentation)至零碎的封包,
這些封包於隧道的另一端接收後再進行重組工作,
將會增加隧道端點的負荷並降低網路傳輸效率,
NVGRE 在內部封裝為 IP 封包時會辨識網路路徑 MTU(Path MTU),
若大於封裝後的長度則會強迫封包維持原狀以避免此分段的情境,
以上兩點均讓 NVGRE 適於在現有網際網路上傳遞。
Tunneling and Network
|
Nov 26, 2013
Virtual eXtensible Local Area Network(VxLAN)
是由 Cisco、VMware、Citrix、Red Hat 等廠商在 2011 8 月所合作提出的 IETF 草案,
目前最新版本為第六版。
欲解決下列問題:
VLAN 數量不足在大型資料中心網路擴展性、隔離性與虛擬機器跨子網路遷移的問題:
傳統資料中心是利用 VLAN 來隔離不同租戶的網路,
但 VLAN 只提供了 12 bit 的 VLAN ID 的範圍用來區分
並希望透過 VxLAN 的機制將多個不同 layer3 的網路共同連結,就像是處在同一個 layer2 的網段。
GRE tunnel 的不足:
看了之前的 後就可以發現,
GRE 是一種 point to point 的 tunnel protocol,
使得在 broadcast 時需要針對每個 node 重複發送。
或許可以透過 GRE broadcast 的特性來擴充,
但是 VXLAN 的外層封裝的 UDP 特性使得在此方面的作用是無法被 GRE 取代的,
除非所有交換器都能察覺被封裝的封包內層資訊。
若要架設一個 VxLAN 需要下元件:
- Multicast support, IGMP and PIM
- VXLAN Network Identifer (VNI)
- VXLAN Gateway
- VXLAN Tunnel End Point(VTEP)
- VXLAN Segment/VXLAN Overlay Network
VXLAN Header format
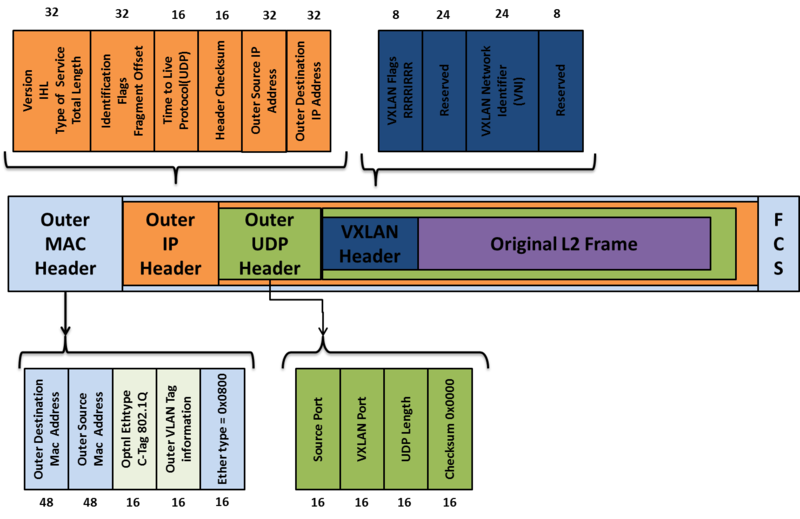
Outer Ethernet Header
Destination Address
用來設定 destination VTEP 的 MAC address,如果 destination VTEP 與 Source VTEP 不屬於同一個 L3 的 domain 下的時候,這個欄位就會用來填入 next hop device(router) 的 MAC addrss。
VLAN
是一個可填可不填的欄位,如果有填的話就會就會利用 ethertype of 0x8100 來實作可隔離網路的 VLAN ID Tag。
Ethertype
在目前是設定 0x8000 格式的 IPv4 的封包,預計在未來的版本將會支援 Ipv6。
IP Header
其實這邊的封包格式與一般 IPv4 的封包格式相同,
只是這邊的傳輸都是建立在 VTEP 與 VTEP 之間。
Protocol
這邊會設定為 0x11 表示,封包裡面的內容是 UDP 封包
Source IP
送出封包的來源 VTEP
Destination IP
目標的 VTEP IP address,如果發送端的 VTEP 不知道的話,會透過下列的步驟來尋找:
發送端的 VM 會透過發送端的 VTEP 會送出 multicast 的封包給同在一個群組下的 VTEP(有著相同 VNI 的 VTEP)。
這些相同群組下的 VTEP 收到封包後,就會學到 soure virtual machine 的 MAC address,與發送端 VTEP IP address 的對應關係。
各 VTEP 會去 mapping 自己下面的 VM 有沒有這個 multicast 封包內的要找的 destination virtual machine, 如果有的話,就會回送一個 response 的封包給發送端的 VTEP,告訴他接收端的 VTEP IP address,
然後發送端的 VTEP 也會學起來 destination virtual machine MAC address 與 VTEP IP address 的對應關係。
UDP Header
整個VXLAN 封包再由外層的 IP/UDP 封包透過第三層實體網路在兩個 VTEP 間傳遞。
Source Port
用來作為 Layer2 trunk 或 L3 multipath 對封包進行 hashing 作為時轉送的依據,
而為了在多路徑的網路環境下等價多路徑路由(Equal Cost Multi-Path,ECMP)達到負載平衡,
建議 VTEP 在設定 UDP 的來源端埠號時參考內部被封裝的封包表頭的雜湊值,
可依此區別不同資料流(flow),確保屬於相同資料流的封包在第三層傳輸的路徑相同,
並讓不同資料流的封包分散至等價的路徑上。
而當封包被封裝完以後 VTEP 會判斷封包的來源與目的決定要透過點播(unicast)或者群播(multicast)來傳遞封包到另外一個 VTEP,
VTEP 的學習機制類似乙太網路交換器,不同的地方在於它是除了 MAC 外再額外加上目的 VTEP 的 IP 來學習,
就是先判斷透過 VNI 找到所有關聯的 VTEP 節點後就能學習到某個目標在哪個 VTEP 了。
VXLAN Port
已向 IANA 申請了4789 作為辨識 VXLAN 的依據。
Checksum
這個欄位應該要被設定為 Ethertype 0x0000,
如果 Source VTEP 不是設定 0x0000 格式的話,
Receiving VTEP 就會去認證 checksum,如果不符合的話,就會丟棄(dropped)這個封包。
VXLAN Header
VXLAN Flags(8bit)
如果 I flag 被設為 1,就一定要去認證 VXLAN Network ID(VNI),
其它 7 個欄位都是保留欄位,目前都被設定為 0。
VXLAN Segment ID/VXLAN Network Identifier (VNI):
24 bit 的欄位,用來代表不同 VXLAN 群組的編號,不同編號的 VNI 群組,不能互相溝通。
可支援超過一千六百萬個不同虛擬網路,遠大於 VLAN 4094 個的限制。
下列會舉一個例子來說明,當兩個屬於同一 VNI 群組下的 VTEP 的 VM 如何互相溝通。
VXLAN Header
VXLAN Flags(8bit)
如果 I flag 被設為 1,就一定要去認證 VXLAN Network ID(VNI),
其它 7 個欄位都是保留欄位,目前都被設定為 0。
VXLAN Segment ID/VXLAN Network Identifier (VNI)
24 bit 的欄位,用來代表不同 VXLAN 群組的編號,不同編號的 VNI 群組,不能互相溝通。
可支援超過一千六百萬個不同虛擬網路,遠大於 VLAN 4094 個的限制。
下列會舉一個例子來說明,當兩個屬於同一 VNI 群組下的 VTEP 的 VM 如何互相溝通。
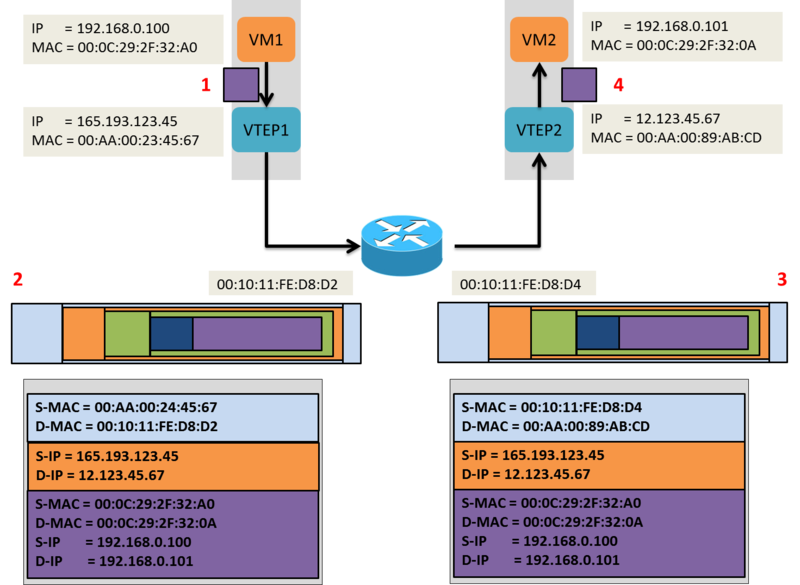
當 VM1 要送一個封包給 VM2 的時候,會透過下列的步驟來知道 VM2 的 MAC address:
- VM1 送出一個 ARP 的封包,去問說 192.168.0.101(VM2) 的 MAC address 是多少。
- 這個 ARP 的封包經由 VTEP1 封裝後,把它塞進 multicast 的封包內,並且送給屬於同一個 multicast group 下的 VTEP( VNI 為 864 的 VTEP)
- 同群組下的 VTEP 收到 multicast 的封包後,會把 VTEP1 跟 VM1 的相關性,(00:0C:29:2F:32:A0是由 IP address 165.193.123.45 這個 VTEP 1 送出來的),記錄在 VXLAN table 內。
- VTEP2 接到這個 multicast 封包後,會解開來,然後送出一個 broadcast 的封包給屬於 VNI 864 portgroups 內的所有 VM。
- VM2 看到這個 ARP 的封包,並且回應他自己的 MAC address(00:0C:29:2F:32:0A)。
- VTEP2 把這個 ARP response 封包後,透過 unicast IP 的封包,送給 VTEP1。
- VTEP1 接到後,解開來,並且把封包 pass 給 VM1。
透過上面的步驟 VM1 已經知道 VM2 的 MAC address 了,並且可以直接送封包給 VM2 了:
- VM1 送一個 IP 的封包給 VM2(Srouce IP address:192.168.0.100, Destation IP address:192.168.0.101)
- VTEP1 把這個封包封裝起來,並且把下列這些資訊加 Header 內:
- VXLAN Header VNI = 864
- 標準的 UDP header 並且把 UDP checkcum 設為 0x0000,然後把 destination port 設為 INAN 認證的 VXLAN port(4789)
- 標準的 IP header 並且設定 destination IP address 為 VTEP2 的 IP address,然後 protocol 設定為 0x11,要使用 UDP 去傳送
- 標準的 MAC header,destination MAC address 為 next hot address,在這個例子看來,就是中間 router 的 MAC address
- VTEP2 接到了從 UDP destination port(4789) 傳進來的 VXLAN 封包後,把封包解開來,然後會去 mapping 屬於 VNI 864 這個 portgroup 的 VM,知道是送給 VM2 後,就把 VXALN 的封包再解開,然後把封包 pass 給 VM2。
- VM2 接到從 VM1 送來的封包,並且不知道中間發生了什麼事(VXLAN 封裝、解封裝的過程)
Tunneling and Network
|
Nov 26, 2013
簡介
Generic Routing Encapsulation(GRE)
是一個由 Cisco 開發的點對點無狀態通道協定(point to point stateless tunneling protocol),
實際運作會將內容封裝到 Layer 3 的 IP 封包中傳送到遠端路由器後解開還原。
GRE header format

如上圖所示經過 GRE 封包的封包會多上一層 GRE 標頭(header),當封包傳送到目的路由器後則進行解封裝,此協定本身沒有加密的功能,但是能搭配 IPSec 來進行安全傳輸,且 GRE 支援多點群播(multicast)和 IPv6。
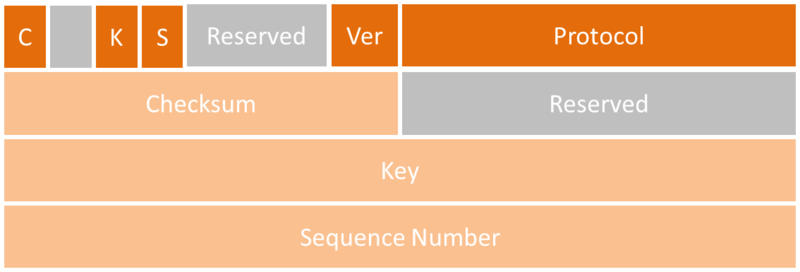
GRE 封包結構如上圖,在 GRE Header 裡面最重要的欄位是 Key,如果 GRE 通道的兩端分別是路由器,則辨別兩端 GRE 通道是否能夠順利通訊的關鍵則是此欄位(Key)要設為相同。
C、K、S:分別代表 checksum、key、 sequence number 的 Bit flages
Ver: GRE 的版本,目前是第 0 版
Protocol: Ethertype of the encapsulated protocol
Checumsum: Packet checksum(optional)
Key:Tunnel Key(optional)
Sequence Number: GRE sequence number(optional)
GRE Tunnel architectural
下圖就是兩台 switch 間建起 gre tunnel 連線後,
不同 domain 的 client 就可以互相溝通了。
與 IP in IP 不同的是,
Gre Tunnel encapsulation、decapsulation Header 是由中間的 middlebox(swtich 或是 route)來做的。
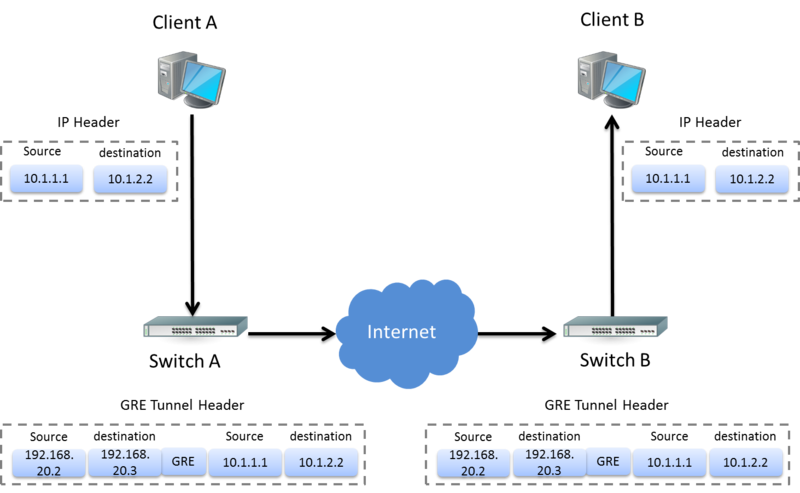
如果用 Wireshark 打開封包來看的話
如下圖:

最下層就是 client 的 srouce、destination IP
中間包了 GRE 的 Header 後
上層就是兩台 switch 的 srouce、destination IP 了
GRE tunnel 的缺點
如果要兩個 host 建立 GRE tunnel 連線的話,會需要一條 GRE tunnel
如果要將三個點連線的話呢?
會需要三條 GRE tunnel 才能連將三個 host 串連,如下圖:
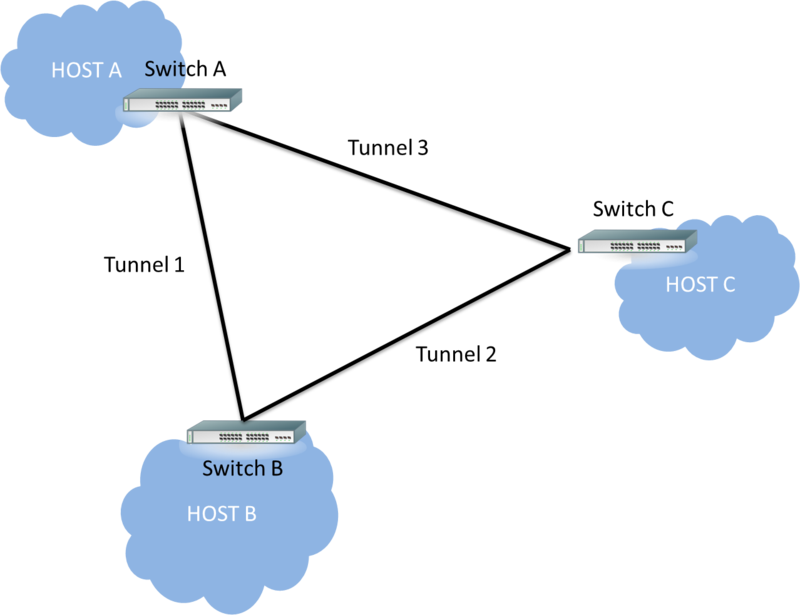
這樣就很容易看出來,
GRE tunnel 的 scalability 太差,
從根本上來說,他只是一個 Point to Point 的 tunnel,
所以在之後的 VXLAN 等等新的 Tunneling 也同時解決了這個問題。
Ref.
Network
|
Nov 25, 2013
一直都搞不太清楚這三者通訊方式的差別,
所以在此記錄一下。
以下會利用下列這個網路拓璞來說明各種通訊方式:
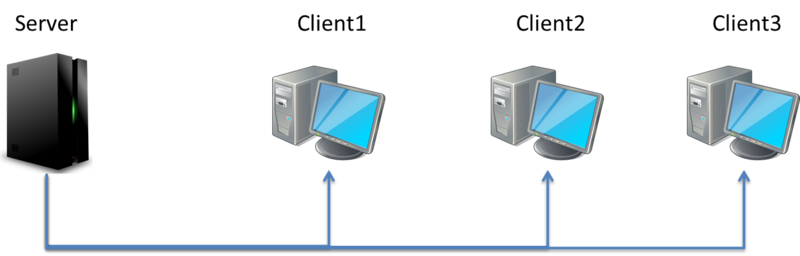
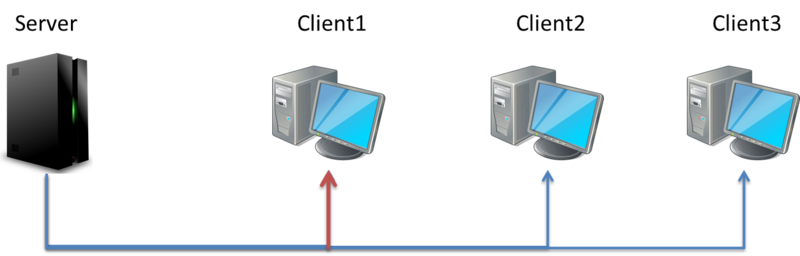
1.Unicast(單傳傳播)
通常指的是特定的目的地位址,一般是主機之間互相傳遞封包的方式,也被稱為 One-to-One 的通訊方式。
連結頻寬 = 單點資料量 * 瀏覽者數量
Server 要向每個 Client 分別傳送文件
同樣的文件要傳輸多次,也就是說網路上的流量就會有
4.5 M = 1.5 M * 3
2.Broadcast(多點廣播)
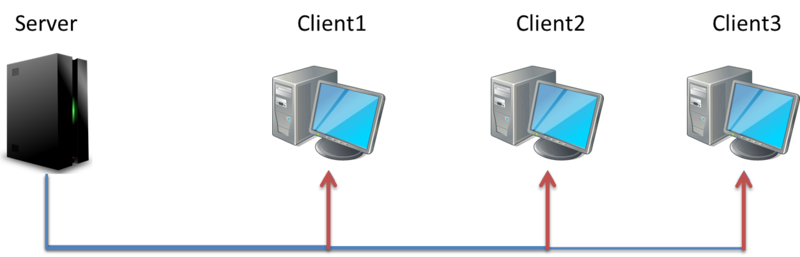
通常發生在 MutiAccess 的網路媒介中。
在 Layer2 中的 Header destination Mac 通常是 FF:FF:FF:FF:FF:FF
在 Layer3 中的 Header destination IP 通常是 255.255.255.255
連接至通一 LAN 網路媒介上的所有主機級網路設備都會接收到這個封包進行行處
比較常件的就是 Arp 的 Broadcast 的封包了
因此被稱為 One-to-All 的通訊方式。
只需發送一個文件,只要是同一個 LAN 中的 Client 都能收到這個訊息
網路間的流量為 1.5 M
3.Multicast(多播/群播)
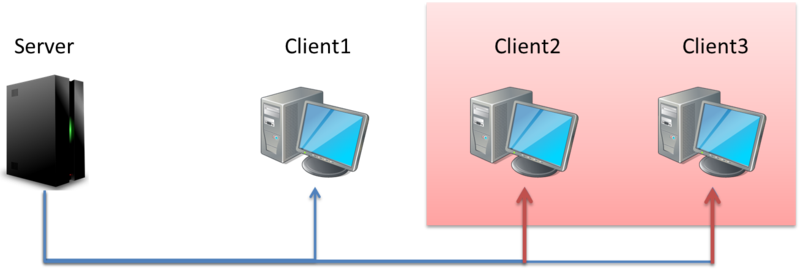
一般應用於相同資料來源同時要傳送給一群特定的 Multicast Group Client,
但是 Server 只會發送一份資料,
因此頻寬的使用量不會因為 Client 增加而增加,
因此也被稱為 One-to-Many or Many-to-Many 的通訊方式
傳輸的方式跟 Broadcast 有點相似,只是不是發給網路中的每一個客戶,
而是誰需要就發給誰,如果 3 個 Client 中只有 2 個需要這個文件,
那麼 Multicast 可以滿足要求,只發給其中的 2 個 Client。
以我們的例子來說:
我們的 LAN 中有 3 台 client,但只有 client2、client3 需要文件
那首先 client2、client3 必須對 server 發出 request,
Server 會根據 Request 回應 Client
Ref.
- 漫談Unicast/Broadcast/Multicast
- unicast、broadcast、multicast